Deploy
ModelZ is an end-to-end platform for developers, that allows you to create and deploy your models to the cloud in just a few minutes.
Sign up
To sign up for ModelZ, go to https://cloud.modelz.ai/signup (opens in a new tab). You can choose to authenticate either with GitHub or by using an email. When using email authentication, you may need to confirm both your email address and a phone number.
Create & deploy a Deployment
Once you have successfully signed up for ModelZ, you're ready to start creating a deployment.
A Deployment is the place where you write your prediction code and deploy it to the cloud. When you visit the dashboard, you'll see a list of all your inference deployments. There are two ways to create a new deployment on ModelZ:
- Use a Template. You could use one of our templates to get started with your deployment.
- Build and deploy a new deployment from scratch. You could visit the Build page to learn how to build a new inference server and push it to a Docker Registry.
Use a Template
ModelZ provides a set of pre-built templates that you could use to get started with your deployment. You could visit cloud.modelz.ai/deployment/template (opens in a new tab) to get all public templates.

You could click on the template to use it. You'll be redirected to the deployment create page, where you could configure your deployment.
Configure your Deployment
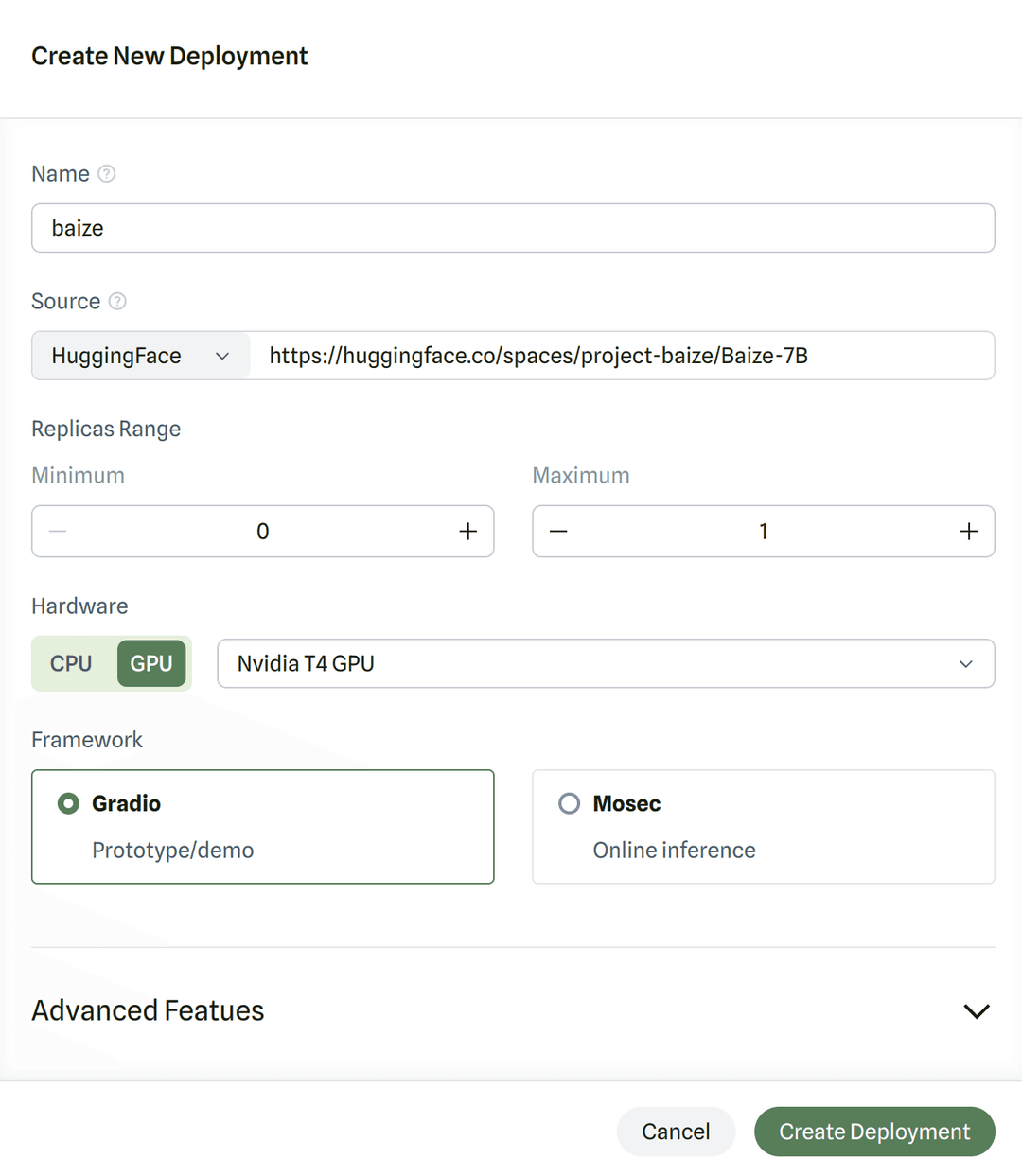
Whenever you create a new inference deployment on ModelZ, the platform will try to preselect the right default configuration for you.
You could deploy the gradio application from huggingface space. You could use the full URL of the huggingface space (e.g. https://huggingface.co/spaces/project-baize/Baize-7B (opens in a new tab)) or the space name (e.g. project-baize/Baize-7B) in the Source field.
Autoscaling
Currently, ModelZ supports autoscaling based on inflight requests. This means that you can configure your inference deployment to scale up or down based on the number of requests that are currently being processed.
You could configure a minimum and maximum number of replicas for your inference deployment. For example, if you set the minimum number of replicas to 1 and the maximum number of replicas to 10, then ModelZ will make sure that your inference deployment always has at least 1 replica running, and at most 10 replicas running.
For more information about autoscaling, you could visit the Autoscaler page.
Get your Deployment URL
Once you have successfully deployed your inference deployment, you could visit the detail page to get the endpoint URL:

You could visit the web UI by clicking on the URL if the deployment is based on Gradio.
Make predictions
Or you could use the URL to make predictions. You can visit the Make Predictions page to learn how to use your deployed inference deployment.